解決策。コメントアウト時のエラー。SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 22-23: truncated \xXX escape
解決策。コメントアウト時のエラー。SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 22-23: truncated \xXX escape
エラー
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 22-23: truncated \xXX escape
エラーになったソース
'''
a = 5
b = r'xyzopqstu\x\y\z'
'''
解決策
コメント内の文字列でエスケープコードが評価されているので、 先頭にrをつける
r'''
a = 5
b = r'xyzopqstu\x\y\z'
'''
コメント
もっといい方法があれば、教えて下さい、是非!。
np.dotや行列積や行列とベクトルの積に関する話
np.dotや行列積や行列とベクトルの積に関する話
最初に、行列積(行列の乗法)に関して
どこかの段階で、行列の掛け算の仕方を学ぶと思うが。。。
(↓ 引用。Wikipedia。
https://ja.wikipedia.org/wiki/%E8%A1%8C%E5%88%97%E3%81%AE%E4%B9%97%E6%B3%95
)

上記の乗算の方法が、唯一の方法というわけではなく、
2つ並べた行列のかけ方には、いろいろある。
引用
数学において、行列の対から別の行列を作り出す二項演算としての行列の乗法は、実数や複素数などの数が初等的な四則演算でいうところの乗法を持つことと対照的に、そのような「数の配列」の間の乗法として必ずしも一意的な演算を指しうるものではない。そのような意味では、一般に「行列の乗法」は幾つかの異なる二項演算を総称するものと考えることができる。行列の乗法の持つ重要な特徴には、与えられた行列の行および列の数(行列の型やサイズあるいは次元と呼ばれるもの)が関係して、得られる行列の成分がどのように特定されるかが述べられるということが挙げられる。
行列とベクトルの積
行列とベクトルの積に関しては、上記で示した、一番有名な行列の乗算に完全に従おうとした場合、
縦ベクトルとか横ベクトルとか、
その場合は、数が合わないのでかけられないとか、
乗算の結果が、横ベクトルになるとか、縦ベクトルになるとか、いろいろあるけれど、、
それは、そんな感じとして、最も、使われる感じでかけてみようというのが、
np.dotのノリのような気がする。
import numpy as np a = np.array([1,2]) b = np.array([[10,20,30],[40,50,60]]) c = np.array([[10,20],[30,40],[50,60]]) p= np.dot(a,b) print(a.shape,b.shape) # (2,) (2, 3) print(p,p.shape) # [ 90 120 150] (3,) q = np.dot(c,a) print(c.shape,a.shape) # (3, 2) (2,) print(q,q.shape) # [ 50 110 170] (3,)
↑ ベクトルは、ベクトルで、縦とか横とか言ってもな。。。というノリか。
2次元配列にすれば、表現はできるが。。。
コメント
コメントなどあれば、是非!!
解決策。OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。
解決策。OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。
エラーの内容
エラーの内容:
解決策。OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。
エラーの詳細:
OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。 Error loading "C:\Python\Python38\lib\site-packages\torch\lib\caffe2_nvrtc.dll" or one of its dependencies. Traceback (most recent call last):
環境
Windows10
(GPUありPCです)
解決策
下記は、途中の様子ですが、以下の数字(初期サイズ、最大サイズ)を両方、5000以上にしました。
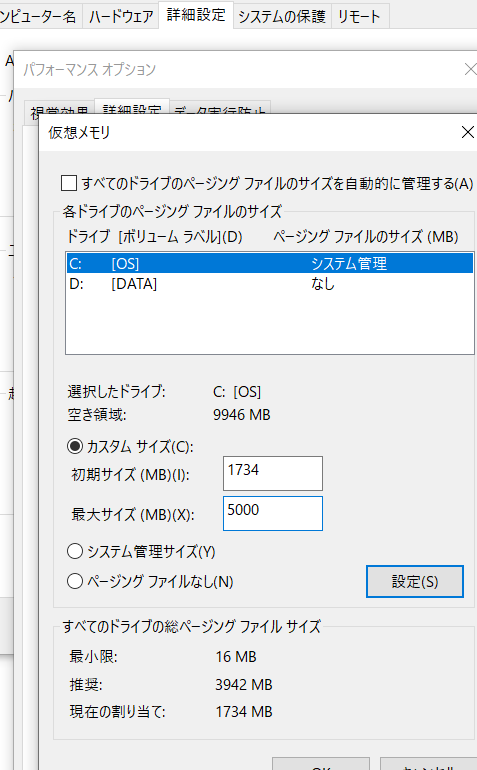
ページング ファイルのことは、あまり、理解していません。 長く使っていたPCで初めての現象なので、 なぜ??という疑問は、まだ、残っていますが。。。 一応、動いたので、「解決策」として記します。
解決策。cv2.error: OpenCV(4.5.3) :-1: error: (-5:Bad argument) in function 'resize'
解決策。cv2.error: OpenCV(4.5.3) :-1: error: (-5:Bad argument) in function 'resize'
エラー
cv2.error: OpenCV(4.5.3) :-1: error: (-5:Bad argument) in function 'resize'
周辺含めた詳細
Traceback (most recent call last):
File "mosaic.py", line 196, in <module>
ErrorList, ImgNumbers, GoodMatches = giveMosaic(img1, 10000)
File "mosaic.py", line 92, in giveMosaic
FirstImage = cv2.resize(FirstImage, (widthM / 4, heightM / 4))
cv2.error: OpenCV(4.5.3) :-1: error: (-5:Bad argument) in function 'resize'
> Overload resolution failed:
> - Can't parse 'dsize'. Sequence item with index 0 has a wrong type
> - Can't parse 'dsize'. Sequence item with index 0 has a wrong type
エラーの内容は、
↓ 下記で、引数がダメ(Bad argument)
FirstImage = cv2.resize(FirstImage, (widthM / 4, heightM / 4))
具体的には、
> - Can't parse 'dsize'. Sequence item with index 0 has a wrong type
dsizeに対する引数のタイプがNG、とのこと。
解決策
このコードは、python2対応で書かれたコードであり、python3の環境で動かそうとしているので 出る。
/を//に変更すれば良い。
FirstImage = cv2.resize(FirstImage, (widthM // 4, heightM //4))
自分の関連記事
Python2のコードをpython3で動かしてエラーが出る場合、こう治せば良い。(AIとかのコード編) - keep-loving-pythonのブログ
コメント
アドバイスなどあれば、お願いします。
Python2のコードをpython3で動かしてエラーが出る場合、こう治せば良い。(AIとかのコード編)
Python2のコードをpython3で動かしてエラーが出る場合、こう治せば良い。(AIとかのコード編)
意外と、以下に示す3つぐらいじゃないでしょうか! 他にも、実体験としてあれば、教えて下さい。
【1】print関連
print "Min and Max:", x_min, y_min, x_max, y_max
↓ 単に、()をつけるだけ
print("Min and Max:", x_min, y_min, x_max, y_max)
【2】range,xrange関連
for i in xrange(0, 10000)
↓ xrangeをrangeにするだけ
for i in range(0, 10000)
【3】【重要】除算関連
a = fun1(b/4)
↓ / を //にかえる。これで、python3でも、整数化される。
これが、原因で、引数NGでエラーが出る場合、結構あります。
a = fun1(b//4)
コメント
意外と、この3つぐらいじゃないでしょうか! 他にも、実体験としてあれば、教えて下さい。
pip、requirements.txt で見かける、"~="の意味は?
pip、requirements.txt で見かける、"~="の意味は?
回答
https://stackoverflow.com/questions/39590187/in-requirements-txt-what-does-tilde-equals-mean を見て下さい。
上記から引用します。
これは、0.6.10 以上で 0.6.* 版のパッケージの最新版を選択することを意味し、例えば 0.7.0 をダウンロードすることはありません。パッケージメンテナがセマンティックバージョニング (メジャーバージョンでのみ変更を加えるべきという考え方) を尊重していれば、セキュリティフィックスを受けつつ後方互換性を保つことができます。
あるいは、PEP 440 で述べられているように。
与えられたリリース識別子V.Nに対して、互換性のあるリリース句は、比較句のペアとほぼ等価です。
= V.N, == V.* とほぼ同じです。
こちらの回答がより見やすいか?引用します。
Adding to the existing answers, I think it's very important to also mention that while
~=0.6.10 means >=0.6.10, ==0.6.*
Following is also true
~=0.6 means >=0.6, ==0.*
コメント
特にありません。
解決策。ImportError: cannot import name 'soft_unicode' from 'markupsafe'
解決策。ImportError: cannot import name 'soft_unicode' from 'markupsafe'
エラーの内容
ImportError: cannot import name 'soft_unicode' from 'markupsafe'
エラーの詳細
Traceback (most recent call last):
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\XYZZ0\AppData\Local\Programs\Python\Python37\Scripts\jupyter-nbconvert.EXE\__main__.py", line 5, in <module>
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\nbconvert\__init__.py", line 4, in <module>
from .exporters import *
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\nbconvert\exporters\__init__.py", line 3, in <module>
from .html import HTMLExporter
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\nbconvert\exporters\html.py", line 11, in <module>
from jinja2 import contextfilter
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\jinja2\__init__.py", line 33, in <module>
from jinja2.environment import Environment, Template
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\jinja2\environment.py", line 15, in <module>
from jinja2 import nodes
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\jinja2\nodes.py", line 19, in <module>
from jinja2.utils import Markup
File "c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\jinja2\utils.py", line 647, in <module>
from markupsafe import Markup, escape, soft_unicode
ImportError: cannot import name 'soft_unicode' from 'markupsafe' (c:\users\XYZZ0\appdata\local\programs\python\python37\lib\site-packages\markupsafe\__init__.py)
解決策
以下のサイトで示されている通りでした。 https://clione.online/pandas_markupsafe-error/
python -m pip install markupsafe==2.0.1
エラー時のバージョン
MarkupSafe 2.1.1
補足(2023/02/11)
同じエラーが出ました。なぜか、以下のバージョンになっていました。
何かと連動してバージョンが上がるのか、何かの都合でバージョンを自分で上げたのだと思います。
MarkupSafe 2.1.2
コメント
アドバイスやコメントがあれば、お願いします。